Shoper – jak wyindeksować niechciane podstrony przez Google Tag Manager?

Shoper jest jedną z najbardziej popularnych platform ecommerce typu SaaS w Polsce. Jako sklep jest dość wygodny w zarządzaniu oraz w samej optymalizacji SEO. Mimo to wymaga optymalizacji Crawl Budget, ponieważ boryka się z problemem indeksujących się stron z mało znaczącym contentem jak: filtrowanie, wyszukiwanie wewnętrzne, koszyk, panel logowania i inne podobne. Oczywiście jest to sprawa umowna każdego z przypadków, ale w skrócie można uznać, że są to podstrony przyblokowane regułą Disallow w pliku robots.txt:
/application /libraries /*/fav/add /*/p/comment/add /*/p/q /*/reg /*/login /*/searchquery /*/basket /*/p/mail/recommend
Google przez indeksowanie i wyświetlanie w SERP’ach tych adresów URL prowadzi do strat strony w przepływie Page Ranku oraz do duplikacji treści. Dlatego jeżeli strona nie posiada dużego Page Authority, zalecane jest zablokowanie robotów w tym obszarze. Dzieje się tak, ponieważ blokowanie konkretnych adresów URL przez robots.txt może nie wykluczać ich przed indeksowaniem. Lepszym rozwiązaniem jest zablokowanie indeksowania strony poprzez zastosowanie tagu noindex.
Niestety przez panel samego Shopera nie jest to możliwe. Z pomocą jednak może przyjść nam Google Tag Manager. Integracja Shopera z Google Tag Managerem jest dość prosta. Pozostaje tylko stworzyć odpowiedni tag i regułę.
Tag: Niestandardowy kod HTML
<script>
var m = document.createElement('meta');
m.name = 'robots';
m.content = 'noindex, nofollow';
document.head.appendChild(m);
</script>

Widok konfiguracji tagu w panelu GTM
UWAGA: to czy chcemy przekazywać Page Rank czy nie, zależy od indywidualnego case study, jednak w większości przypadków warto optymalizować Crawl Budget, stosując meta robots noindex, nofollow. Jeśli chcemy inaczej, należy edytować piątą linie skryptu.
Reguła: Wyświetlanie strony
Page URL dopasowane do wyrażenia regularnego (bez uwzględniania wielkości liter)
/*/Basket|/*/basket|/*/reg|/*/p/comment/add|/*/p/mail/recommend/|/*/fav/add/|/*/p/q|/*/login|/*/searchquery|/panel/*|/application|/libraries|/application|/environment
Page URL niedopasowane do wyrażenia regularnego (bez uwzględniania wielkości liter)
/environment/cache/images

Widok konfiguracji reguły w panelu GTM
Następnie zapisujemy i publikujemy zmiany.
UWAGA: gotowy plik .json z kontenerem i tagiem blokujący przed indeksowaniem wszystkich stron z domyślnego pliku robots.txt Shopera (aktualny na dzień publikacji artykułu) do zaciągnięcia przez Import kontenerów GTM znajduje się na końcu artykułu.
Musimy tylko pamiętać, że gdy chcemy wyindeksować zaindeksowane podstrony, należy najpierw je odblokować w pliku robots.txt, aby GoogleBot mógł je ponownie sprawdzić, a następnie wyindeksować. Dlatego na jakiś czas należy wyczyścić plik robots.txt z reguł: Disallow, a po wyindeksowaniu podstron plik przywrócić.
Plik robots.txt w nowym panelu Shoper edytujemy: Konfiguracja > Marketing > Pozycjonowanie > Zaawansowane
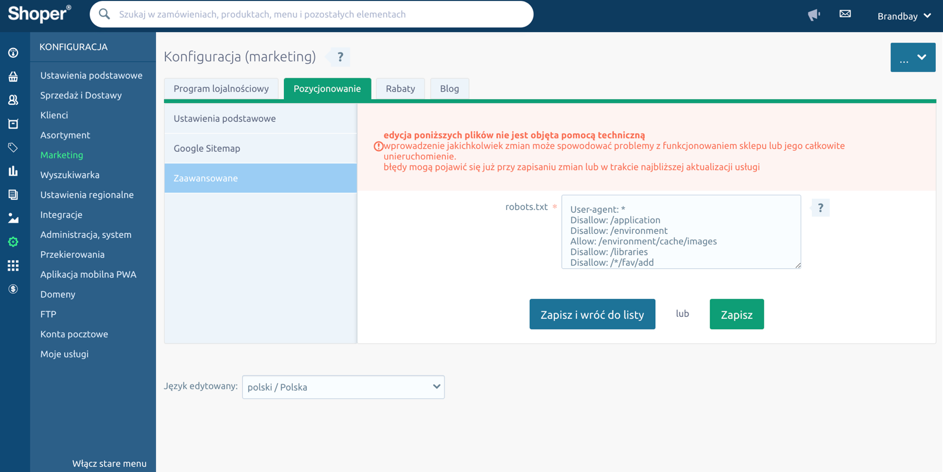
Widok konfiguracji robots.txt w panelu Shoper
Sam skrypt tagu jest uniwersalny, tak więc jest możliwość zastosowania go w innych platformach typu SaaS i nie tylko. Należy edytować odpowiednie reguły wyświetlania się. Konfiguracje meta tagu robots przez GTM należy traktować jako ostateczność. Jeżeli jesteśmy w stanie wdrożyć je przez fizyczną edycje plików na serwerze – powinniśmy tego dokonać.
Pobierz: GTM-robotsnoindexshoper.json



Info od Google:
Google states that using JavaScript to remove or change the robots meta tag may not work the way you expect it to, explaining, “Googlebot skips rendering and JavaScript execution if the meta robots tag initially contains ‘noindex’. If you want to use JavaScript to change the content of the robots meta tag, do not set the meta tag’s value to ‘noindex’.”
I jak to się ma do podanego sposobu?
Marku, dziękuję za komentarz – masz sporo racji, jednak Google znów pokazuje, że jest pełne sprzeczności. Na testowanych kilku przykładach, nam wdrożenie meta robots przez GTM zadziałało i zablokowane w pliku robots.txt podstrony zaczęły znikać z indeksu. I tak nie mieliśmy za bardzo wyjścia (przez ingerencje w kod skina Klient tracił gwarancje) więc działaliśmy. Podtrzymujemy oczywiście to co napisaliśmy w ostatnich zdaniach:
Dzięki, ważne że działa 😉
Dzięki. A jakby ta formuła miałaby wyglądać dla strony informacyjnej jak na przykład koszty dostawy czy numer konta?
Marku, podaj proszę nazwy adresów URL po / to Ci podpowiemy, albo działaj według wzoru dla np.:
https://brandbay.pl/blog/shoper-jak-wykluczyc-strony-z-wyszukiwarki-google-za-pomoca-gtm/
dodaj do reguły:
Dzięki ale nie działa mi to niestety. Tag jest taki jak podałeś. Reguła Page URL niedopasowanie do wyrażenia regularnego /Koszty-dostawy/
Marku, wygląda na to, że sprawa wymaga głębszej analizy. Napisaliśmy Ci maila z prośbą o podesłanie adresu URL w celu sprawdzenia.
Posiadam inny case. Co jeśli nie chce indeksować strony np. koszyk, ale domyślnie na wszystkich podstronach znajduje się dyrektywa:
? Wielkie dzięki z góry za pomoc!
Ilono, dzięki za pytanie. Poniższy skrypt powinien podmienić obecny tak meta robots index, follow na noindex, nofollow
< script> var element = document.querySelector('meta[name~="robots"]'); element.content="noindex, nofollow" < /script>*usuń spacje za dzióbkiem ‘< ' przed otwarciem i zamknięciem script
Daj znać czy Ci zadziałało.
Wielkie dzięki! 🥰 Devtools pokazuje, że działa.
Czy w ten sposób można by było wyindeksować kolejne strony paginacji ze sklepu na platformie Shoper?
Witam czy jest możliwość skorzystania z Państwa pomocy przy wyindeksowaniu w postaci wykonania usługi lub np wideo konferencji ze szczegółowym opisem krok po kroku jak wykonać wyindeksowanie ?
Prosimy o napisanie więcej szczegółów na adres e-mail: kontakt@brandbay.pl